
Overview
Graph Data in Neo4j
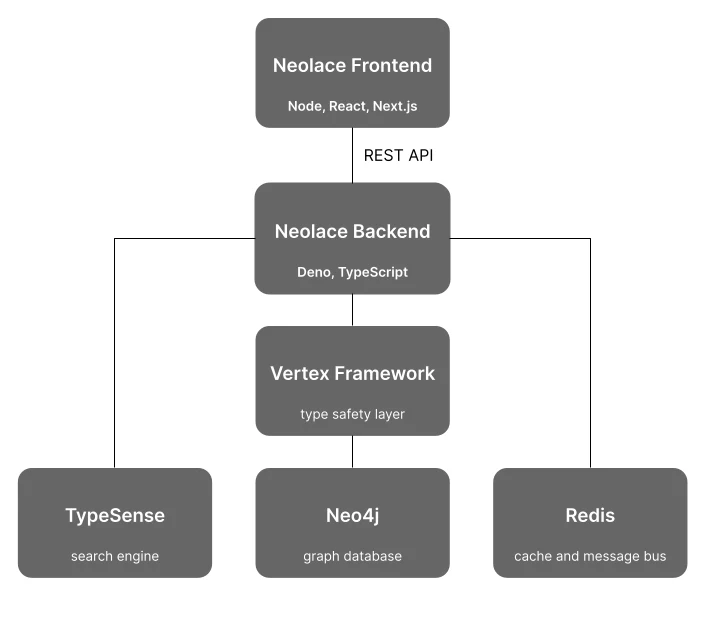
All Neolace data is stored in the Neo4j graph database.
Rationale:
- The highly interconnected datasets that Neolace is designed for are most naturally represented as a graph.
- Neo4j is the only production graph database that fully supports Cypher, which is the graph query language preferred by the Neolace developer team.
- Neo4j has transactions, triggers, and horizontal scaling.
- The Neo4j core is open source.
- Neo4j is a mature technology trusted at enterprise scale.
Vertex Framework
Neolace interacts with Neo4j via an intermediary framework called Vertex Framework.
All data is represented as either a node in the graph or a relationship between nodes. Neolace (and Vertex Framework) use only strongly typed nodes, which are called "VNodes". Each type of node (each VNodeType) has a label (e.g. Entry), a schema (set of allowed/required properties and relationships), and validation (arbitrary code to check constraints).
Every VNode ("object") is identified by a unique identifier called a VNID.
- Neo4j node IDs are meant for internal use only and are not suitable for this purpose (they can be recycled etc.)
- VNIDs are a type of UUID which means that API clients can generate their own IDs in advance of writing to the database, which can be handy for e.g. offline edits.
Some Neolace entities (e.g. Entries, Sites, Users) also have a key, which is a short string with no spaces (like a user name) that uniquely identifies that entity. Unlike VNIDs, the key can be changed.
For details on VNodes and Vertex Framework, see the Vertex Framework documentation.
Reading Data
Any code in the application is welcome to read from the Neo4j graph database at any time, and use any methods to query the nodes and relationships in the database.
Writing/Mutating Data: Actions
A migrations framework is used to define the database schema and apply some occasional data migrations. Other than that, all changes (writes) to the database are done via "Actions". An Action is a mutation to the database such as "Create User", "Edit Article", etc.
- This "Actions" framework is an instance of the "command pattern". It provides consistency (all mutations happen via the same mechanism), auditability, history, and reversability.
Each Action tracks carefully which VNodes it modifies, and then validation of each modified VNode is done before the write transaction is committed. Every Action successfully applied to the graph is itself a VNode, written into the graph, with a MODIFIED relationship pointing to each VNode it created, modified, or deleted.
- This provides a complete change history of every VNode and its relationships.
- This provides fairly strong schema enforcement which Neo4j otherwise does not support (although changes to the validation schema do not apply retroactively, and it relies on actions accurately declaring which VNodes they have modified).
Actions can generally be "inverted" to create a new Action that undoes the original action. This, in combination with the Action log/history, allows auditing and reverting changes to the graph as needed.
Neolace Backend
The "backend" is the application which reads and writes the graph database and provides a REST API for interacting with it.
The backend is implemented as a Deno application written in TypeScript.
The backend uses Drash as its web framework.
The backend delegates authentication to the AuthN microservice.
- This reduces potential for authentication vulnerabilities.
REST API
The backend provides a REST API.
The REST API follows some specific conventions:
- Although the platform itself has i18n features, the API is not multilingual; error messages will only be in English, for example. However, every API response should include machine-readable fields (like error codes) that can be easily converted to localized messages by any frontend.
- Field names are
camelCase - When the Neolace server wants to indicate that a field has a non-value, that field will be present with a
nullvalue.- This applies to string types as well, and strings will generally use
nullinstead of an empty string ("") unless there is a very good and well-documented reason to distinguish betweennulland"". - This makes all the types consistent.
- One reason for this is that a string field with type
stringdoesn't indicate if an empty string is valid or not, but a string field with typestring|nullclearly indicates that the value may sometimes be not set.
- This applies to string types as well, and strings will generally use
- If a field is excluded from the response (or has the value
undefinedwhen returned by the API client), that field may or may not have a value - the API consumer would have to make another request and explicitly include that field in order to know. In other words, absence of a field never implies that it isnull.
For now, in lieu of an auto-generated OpenAPI spec, Neolace provides a hand-authored TypeScript API Client library. The reasons for this are:
- Allows better specification of types than is possible through OpenAPI
- Creates simpler and cleaner TypeScript code
- The API client's types can be used on the API server itself, for compile-time validation
- An OpenAPI spec can always be added in the future.
For now, there is no GraphQL API.
- We have a strongly typed schema for the REST API already
- REST can do a lot of what GraphQL does, such as filtering by fields
- GraphQL is more complex than REST
- GraphQL allows users to send arbitrary queries which may be expensive, unlike REST API queries which are more well-defined and tuned.
Neolace Frontend
The frontend is implemented as a React application written in TypeScript, using the Next.js framework.
- React is a stable, flexible, familiar frontend framework
- Most Neolace traffic is expected to be reads of (relatively) static content, and Next.js excels at optimizing for that case with incremental server-side generation.
- Next.js has lots of developer-friendly features like live-editing/hot-reloading.
- Next.js abstracts away a lot of complexity like webpack and babel, which are annoying to maintain.